I recently had the desire and need to create a ranking algorithm for a side project I was working on. I wanted to keep both the design and implementation fairly simple for my project, so I think this post will be great for people wanting to get their toes wet.
The ranking algorithm I ended up building is used for ranking user-created content – similar to the ranking of posts on sites like Reddit or Hacker News. So one might describe it as a ‘hotness ranking‘ opposed to a ‘relevancy ranking’ used in search engines.
My goal is to walk through the basics of designing a ranking algorithm and then sharing my experiences and findings from implementing my algorithm. My implementation was done for a web application using Node.js and MongoDB.
Designing the ranking algorithm
When starting to design my algorithm, I naturally wanted to understand how other sites’ ranking algorithms worked, fortunately I found a couple of blog posts that provided great introductions for ranking algorithms used by both Reddit and HackerNews. I would also recommend reading this blog post that describes the design process around Reddit’s ‘best’ comment ranking algorithm.
The factors
The first thing to do is to decide what factors you want to actually influence your rankings. For my specific case, I settled on 5 inputs:
- P: Number of points (like upvotes or likes)
- C: Number of comments
- V: Number of views
- Tc: Time since creation
- Tu: Time since last update
For my simple ranking algorithm, I split the inputs into two categories: the score and the decay. The score is what drives an items’ ranking to the top. The decay is what eventually brings it down.
The score
I felt that having a person like or upvote something should easily be the most influential factor for the score, however, I did not want that to be the only factor. I was already tracking views and comments in my application, so I felt that it made sense to include those in the ranking as well. I felt comfortable having those 3 inputs make up the score for a ranking.
The decay
The next step is to decide how you want your rankings to fall over time. Depending on the type of content you are ranking, you might not even want your rankings to decay at all. However, in that case, you may want to skip the rest of this post and just use a simple sort in your database query. For my case, I wanted my algorithm to have rankings decay substantially in roughly 24 hours. In order to achieve this, I followed the HackerNews algorithm pretty closely.
Another factor that was relevant for my side project, was that users would likely update their existing content at some point. I wanted the ranking algorithm to account for this by giving newly updated content a boost in ranking. Since my application stores the datetime for the last update, I use it to generate a value that would be subtracted from the decay caused by the creation datetime.
The algorithm

The result

Implementing the ranking algorithm
Once you have designed your algorithm, you can then start to think about your implementation. The first question that will come to mind is where the algorithm should be implemented. There are 3 main areas to consider: client, server, and database. I think we can pretty quickly disregard implementing the ranking algorithm in the client-side code for a couple reasons:
Reason 1 – If you are wanting to rank thousands of items, you would need to send all of that data over the network to be processed. This would be harmful to your application’s performance and would cause unnecessary load on the network.
Reason 2 – You likely do not want users to have full access to your ranking algorithm, this could make it easier for some users to abuse potential weaknesses of your algorithm.
The next place to consider would be implementing the algorithm is in the server. The way that this implementation would likely work would be to fetch the data from the database then run that data through your algorithm. The output would be your data sorted by ranking. But what if you had millions of records stored? You probably would not want to fetch all your data and run it through the algorithm – especially if your ranking algorithm was relatively complex. This could be especially harmful to your application’s performance if you are using a Node.js in your backend. A possible way to workaround this would be to only fetch a subset of the data, ignoring very old or stale content. That workaround only works if you can be absolutely certain that you can safely ignore the stale content – so that solution may be very narrow. Another solution would be to use server-side caching on your results to reduce overall CPU usage.
Lastly, your algorithm could be placed in the database layer of your application. There are two main approaches for this:
Approach 1 – Implement your ranking algorithm as part of your database query.
Approach 2 – Run a job that calculates ‘ranking’ for each item and updates that field in your database. Then simply query your data and sort by ranking.
With Approach 1, there are some important things to consider. Depending on your database and the complexity of your ranking algorithm it may not be trivial – or even possible – to fully implement it as a query. For example, in version 3.0 and earlier, MongoDB did not support the ‘exponent’ operator when performing aggregation queries ($pow was added in v3.2). This was an actual issue I came across in my implementation – which I will cover in more detail later. So it is entirely possible that your algorithm may need to be revised to fit the limitations of your database. Another important thing to consider would be the performance of your queries. Depending on both the complexity of your algorithm and the amount of data you are ranking, Approach 1 could see come performance issues. However, if your project has a simple algorithm and you don’t expect large amounts of data (100K+), this may be the simplest and most effective solution.
Moving on to Approach 2, it is clear that this approach requires more effort because you need to create a task that will be able to run fairly frequently on its own. However, once that part is complete, querying and sorting your data will be trivial because each item will have an up-to-date ranking field. The downside of this approach is that your rankings will not always be accurate. If you have your job run in 5-minute intervals, then you will allow for the possibility of having rankings that are 5 minutes out of date.
The result
For my project, I wanted to keep things simple and keep my velocity high (as I had a specific release date in my mind). I also knew that I would most likely be dealing with < 100,000 items to rank (at least for long time). I ultimately decided to implement my algorithm as a part of my database query (Approach 1).
Due to the fact that my project was built using MongoDB v.3.0, I did not have access to the $pow operator. As a result, I decided to modify my algorithm to accommodate the limitation.
Here is my updated algorithm:
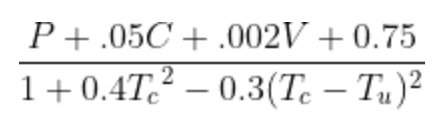
Here is the code for my implemented ranking algorithm:
Item = mongoose.model('Item'),
/*
params.type - String
params.limit - integer
*/
function getRankedItems(params, callback) {
if(params.type === 'all') {
params.type = { $exists: true };
}
Item.aggregate([
{ $match:
{ isDeleted: {$ne: true}, type: params.type }
}, //end $match
{ $project:
{
item: "$_id",
ranking: {
$divide: [
{ $add: [
"$upvotes",
{ $multiply: ["$numComments", 0.08] },
{ $multiply: ["$views", 0.002] },
0.75
] }, //end $add
{ $add: [
1,
{ $subtract: [
{ $multiply: [ // this is a workaround for mongo version 3.0 (no $pow)
{ $multiply: [
{ $divide: [{ $subtract: [ new Date(), "$createDate" ] },14400000]},
.4
] }, //end $multiply
{ $multiply: [
{ $divide: [{ $subtract: [ new Date(), "$createDate" ] },14400000]},
.4
] } //end $multiply
] }, //end $multiply
{ $multiply: [ // this is a workaround for mongo version 3.0 (no $pow)
{ $multiply: [
{ $subtract: [
{ $divide: [{ $subtract: [ new Date(), "$createDate" ] },14400000]},
{ $divide: [{ $subtract: [ new Date(), "$lastUpdate" ] },14400000]}
] }, //end $subtract
.3
] }, //end $multiply
{ $multiply: [
{ $subtract: [
{ $divide: [{ $subtract: [ new Date(), "$createDate" ] },14400000]},
{ $divide: [{ $subtract: [ new Date(), "$lastUpdate" ] },14400000]}
] }, //end $subtract
.3
] } //end $multiply
] } //end $multiply
] } //end $subtract
] } //end $add
] } //end $divide
}
}, //end $project
{ $sort: { ranking: -1 } },
{ $limit: parseInt(params.limit) }
],
function(err, results) {
if (err) {
console.log(err);
return callback(err);
}
callback(null, results);
}
); //end Items.aggregate
}
A few notes on my implementation:
- I am using Mongoose in my application, thus you see the
Itemschema being used. If you are not using mongoose, you can simply replaceItemwith thedb.collection. - I have mentioned my workaround of MongoDB 3.0 not having $pow. If you are using MongoDB 3.2 or higher, replace the $multiply operators that I have labeled with comments with $pow.
- Currently, this implementation returns an array of objects that contain just two fields:
rankinganditem. Therankingfield will hold a float value with the calculated ranking of the item. Theitemfield will simply hold the id of the record. If you find that you need to return more fields, add them to the $project object. - I measured my time in 4 hour units. That’s why you see me dividing the times by 14400000, which is the number of milliseconds in 4 hours. Feel free to play around with this number in your own implementations.
Final thoughts
The ranking algorithm from this article is certainly not perfect; there are a lot of ways to improve it. Rather than just counting all upvotes the same, you could make your algorithm more dynamic by considering vote velocity. If an item receives a ton of upvotes in a short amount of time, then you could have their weight increase. You could also consider the age of vote by giving more weight to newer votes.
The examples in this post only consider upvotes, but what if you want to hide items? Implementing downvotes is one way to allow your users to have even more control curating your rankings. Another common concept is flagging or penalizing items. There could be user-created content that needs to be moderated, having a way to quickly remove or downgrade an item could be important.
If you want updates from me on my future blog posts or on my future projects, please sign up for my email list below!

I was looking for something exactly like that, thanks!!!
LikeLike
Really good stuff.
LikeLike
Hi, thank you for the article, if i could ask about which software does you use to plot the algorithm data ?
LikeLike
Hi Lucas, thanks for reading 🙂 I used http://www.desmos.com/calculator for my graph.
LikeLike
Thank you soooo much! I was going back on whether to use aggregation vs map reduce in mongo. Thanks!
LikeLike
Hi Justin, I am impressed with your work; R U open to start a new project?
LikeLike
Thank you for this brilliant article! I’m in the exact same psition as you were before designing the algorithm but with one difference – i don’t want to consider update time. Would it be hard to rewrite your algorithm to not care about the update time? Sorry for this ignorant question, i’m pretty bad in doing a math like that 🙂 Thanks!
LikeLike
Yeah totally, if you remove the “(Tc – Tu)^2” part of the denominator and basically only decay based on Tc, then you will not be affected by update time.
Sorry for my delayed response, hope that helps.
LikeLike
Hi, thanks for posting this guide. I need something very similar but do not have the technical skills and wondered if you are available to assist but cannot see how to contact you. If you are available can you give me an email or another contact method so I can get in touch with more details…? Thanks!
LikeLike
Please explain how you arrived at your exact formula for the algorithm
LikeLike
Hi Ashutosh, my process involved graphing out my equation so I could see a graph of the ranking and decay of it. Then I just would tweak the weight of the factors. For example, I wanted to consider both views and comments in my ranking, but I knew it didn’t make sense to weigh them as high as the upvotes.
Figuring the ideal time decay was trickier, but I followed the same process. I needed to decide at what time would an item start to accelerate decay in rank. For example, you probably don’t want a popular item to fall out of the front page after just a couple of hours. I think it depends on how often your users visit your website. If they check once a day, then you probably want really popular items to stay on the front page for about 24 hours. If most people only visit every few days, then you likely will want to extend that. Once you determine that, then it really just takes some manual tweaking and viewing how it affects the graph.
Hope that helps!
LikeLike
I don’t see how you handle decay. Or is that part of the ranking algorithm?
LikeLike
Decay is handled by the bottom half of the formula (Tc and Tu). The top half is more or less the weighted score of the item being ranked. The bottom half becomes larger as time passes. Since the top half is divided by the bottom half, as the bottom half increases with time, it will cause the ranking score to decay over time.
Hope that helps!
LikeLike
Like everyone else I’m wondering how you created that formula for the algorithm. Could you explain that.
LikeLike
Hi Gershom, please view my response above to Ashutosh. Let me know if you have other questions.
LikeLike